파이썬을 이용한 정렬 알고리즘
by Seongjae Moon
어떤 프로그래밍 언어에서나 정렬 알고리즘은 중요한 이슈이며, 많은 개발자들이 이미 평균적으로 최적의 알고리즘(최대 O(nlogn)의 시간 복잡도를 가지는)방법을 구현해냈다.
많은 언어가 정렬을 편하게 하도록 내장된 메소드를 제공하고 있지만, 코딩을 하다보면 내장 메소드로만은 해결 불가능한 경우가 있다.
알고리즘 중에 기초 중에 기초?라고 여겨지는 정렬 알고리즘에 대해 시간복잡도와 함께 정리하고자 한다.(코드 예시는 Pycharm을 통해 코딩 되었으며, python 3.6.3 환경에서 작성되었다.)
우선 시간 복잡도에 대해 간단하게 정리하고 넘어가도록 한다.
시간 복잡도란, 실행시간 이라는 관점에서 알고리즘의 효율을 측정하는 방법으로, 쉽게 말해 내가 쓴 코드가 결과물을 뱉어내기까지 얼마나 걸리나를 나타내는 수학적 지표라고 할 수 있다. 어떤 인자 값을 계산하게 될지 모르므로, 매번 같은 실행 시간을 보장하진 않지만 여기서 표현한 빅오 표기법은 최악의 경우 얼마나 오랜 실행 시간이 걸릴 수 있는지를 고려한다고 생각 하면 되겠다.
- O(1) – 상수: 입력값 n이 주어졌을 때, 알고리즘이 문제를 해결하는데 오직 한 단계만 거친다.
- O(log n) – 로그: 입력값 n이 주어졌을 때, 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어든다.
- O(n) – 직선적: 문제를 해결하기 위한 단계의 수와 입력값 n이 1:1 관계를 가진다.
- O(n^2) – 2차: 문제를 해결하기 위한 단계의 수는 입력값 n의 제곱이다.
- O(n^3) – 3차: 문제를 해결하기 위한 단계의 수는 입력값 n의 세제곱이다.
- O(2^n) – 지수: 문제를 해결하기 위한 단계의 수는 주어진 상수값 2 의 n 제곱이다.
성능 순서 : [좋음] O(1) - O(logn) - O(n) - O(nlogn) - O(n^2) - O(n^3) - O(2^n) [나쁨]
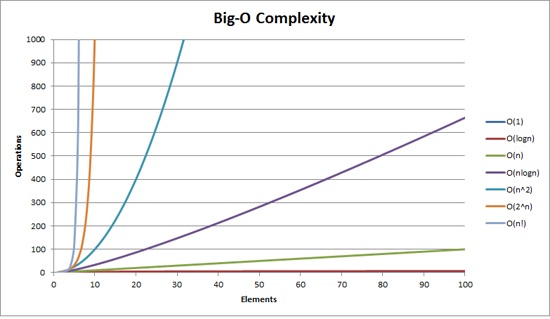
대개의 경우 입력 값의 종류보다 실행 속도가 우선시 되는 경우가 많을테니 실행 속도가 n^2 이상 발생할 수 있는 알고리즘은 사용하지 않는 것이 심신에 좋다고 할 수 있다.
또한, 고려 사항 중에 안정 정렬과 불안정 정렬이라는 것이 있다. 쉽게 말해 먼저 정렬이 끝난 동일한 값의 친구가 있는데 나중에 정렬된 친구와 위치가 바뀌지 않으면, 안정 정렬이다. 굴러온 돌이 박힌 돌을 빼내면 불안정 정렬이라고 할 수 있다.
그렇다면 평균적으로 실행 속도가 어떤 식으로 차이를 발생 시킬 수 있는지 비교 분석 해보고자 한다.
1. 삽입정렬
삽입 정렬은 안정 정렬이며, 값의 양이 길어질수록 효율이 극악으로 떨어진다. 구현이 간단하다는 장점이 있다. 최대 O(n^2) 시간복잡도를 갖는다.
import random # random 메소드 사용을 위해 import
a = random.sample(range(1, 10), 5) # 1<= x < 11의 난수 5개 리스트로 생성
print(a)# 정렬 전 리스트
print('')
for i in range(1, len(a)): # 리스트의 크기만큼 반복
for j in range(i, 0, -1): # j 인덱스의 값이 줄어드면서 삽입할 위치를 찾을 때까지 반복
if a[j] < a[j-1]: # 현재 인덱스가 앞의 원소보다 작다면
a[j], a[j-1] = a[j-1], a[j] # swap해서 값 뒤로 밀어내기
else : break # 불필요한 반복을 피하기 위해 break
print('')
print(a)# 정렬 후 리스트 출력
#출력
[8, 9, 3, 1, 6]
[1, 3, 6, 8, 9]
2. 거품(버블)정렬
거품 정렬은 안정 정렬이며, 모든 원소를 하나하나 비교하여 swap 하는 작업을 반복하는 정렬 방법이다. 개인적으로 구현 방법이 가장 단순하다. 최대 O(n^2) 시간복잡도를 갖는다.
import random # random 메소드 사용을 위해 import
a = random.sample(range(1, 10), 5) # 1<= x < 10의 난수 5개 리스트로 생성
print(a) # 정렬 전 리스트
print('')
for i in range(1, len(a)): # 리스트의 크기만큼 반복
for j in range(0, len(a)-1): # 각 회전당 정렬이 끝나지 않은 친구들을 위해 반복
if a[j] > a[j+1]: # 현재 인덱스의 값이 다음 인덱스의 값보다 크면 실행
a[j+1], a[j] = a[j], a[j+1] # swap해서 위치 바꾸기
print('')
print(a) # 정렬 후 리스트
#출력
[4, 9, 2, 5, 7]
[2, 4, 5, 7, 9]
3. 선택정렬
선택 정렬은 불안정 정렬이며, 나보다 작은 항목을 선택하고 자기자리로 바꾸는 정렬이라고 할 수 있다. 각 회전 단계마다 다음으로 작은 값을 찾아서 이를 올바른 위치에 갖다 놓는다. 최대 O(n^2) 시간복잡도를 갖는다.
import random # random 메소드 사용을 위해 import
a = random.sample(range(1, 10), 5) # 1<= x < 10의 난수 5개 리스트로 생성
print(a)# 정렬 전 리스트
print('')
for i in range(len(a)-1): # 리스트의 크기-1만큼 반복
for j in range(i+1, len(a)): # 해당 인덱스+1부터, 리스트 크기만큼 반복
if a[i] > a[j]: # 인덱스의 값이 비교 인덱스보다 더 크다면
a[i] , a[j] = a[j], a[i] # swap 해주기
print('')
print(a) # 정렬 후 리스트
#출력
[8, 4, 7, 2, 3]
[2, 3, 4, 7, 8]
4. 퀵정렬
퀵정렬은 불안정 정렬이며, 재귀 함수를 통해 구현되며, 이름에서 느껴지듯 상대적으로 빠른 정렬 방법이다. 데이터양이 N배 많이 진다면, 실행 시간은 N배 보다 조금 더 많아 지는 특징이 있다. (정비례 하지 않는다.) 퀵소트는 재귀함수를 이용해서 작성! 최대 O(nlogn) 시간복잡도를 갖는다.
import random # random 메소드 사용을 위해 import
a = random.sample(range(1, 10), 5) # 1<= x < 10의 난수 5개 리스트로 생성
print(a) # 정렬 전 리스트
print('')
def quickSort(a, start, end):# 재귀함수용 함수 선언(리스트, 시작인덱스, 종료인덱스)
# print(a)
if start < end: # 시작 인덱스 보다 끝 인덱스가 클 경우
left = start # left 변수에 시작 인덱스 할당
pivot = a[end] # //pivot 값은 a리스트에 마지막 원소 값
for i in range(start, end): # 시작인덱스부터 끝 원소까지 반복
if a[i] < pivot: # 리스트 인덱스 값이 pivot 값보다 작을 경우라면
a[i], a[left] = a[left], a[i] # 해당 인덱스와 left인덱스 swap
left += 1 # 인덱스 하나 증가 시켜주기(자리를 옮겨가며 비교해야 하기 때문에)
a[left] , a[end] = a[end], a[left] # left인덱스와 끝 인덱스 swap
print(left)
quickSort(a, start, left-1) # 재귀 호출 (리스트, 시작 인덱스, left-1)
quickSort(a, left+1, end) # 재귀 호출 (리스트, left+1, 종료인덱스)
quickSort(a, 0, len(a)-1)
print('')
print(a) # 정렬 후 리스트
#출력
[8, 1, 7, 2, 5]
[1, 2, 5, 7, 8]
5. 병합(머지)정렬
병합 정렬은 퀵 정렬과 마찬가지로 재귀함수를 이용해서 구현할 수 있으며, 마찬가지로 데이터 크기만큼의 스택 메모리가 필요하다. 리스트를 두 부분으로 쪼개서 작은 값부터 하나하나 병합하는 정렬 방법이다.
O(log n)의 시간 복잡도를 갖는다 오?
import random # random 메소드 사용을 위해 import
a = random.sample(range(1, 10), 5) # 1<= x < 10의 난수 5개 리스트로 생성
print(a) # 정렬 전 리스트
print('')
def mergeSort(a):
if len(a) > 1: # 배열의 길이가 1보다 클 경우 재귀함수 호출 반복
mid = len(a)//2 # 2로 나눈 몫 (중간 값) 취함
la, ra = a[:mid], a[mid:] # la 중간 값을 기준으로 왼쪽, ra 중간 값을 기준으로 오른쪽
mergeSort(la) # 왼쪽 서브 리스트의 값을 기준으로 병합정렬 재귀 호출
mergeSort(ra) # 오른쪽 서브 리스트의 값을 기준으로 병합정렬 재귀 호출
li, ri, i = 0, 0, 0 # 정렬을 위한 변수 선언 (왼쪽, 오른쪽, 기준)
while li < len(la) and ri < len(ra): # 서브 리스트의 정렬이 끝날 때까지 반복
if la[li] < ra[ri]: # 오른쪽 리스트의 값이 클 경우라면
a[i] = la[li] # 왼쪽 리스트의 해당 인덱스의 값을 할당
li += 1 # 왼쪽 리스트의 인덱스 하나 증가
else: # 왼쪽 리스트의 값이 클 경우라면
a[i] = ra[ri] # 오른쪽 리스트의 해당 인덱스의 값을 할당
ri += 1 # 오른쪽 리스트의 인덱스 하나 증가
i += 1 # 기준 인덱스 증가
a[i:] = la[li:] if li != len(la) else ra[ri:]
# 왼쪽 리스트의 인덱스의 값이 서브 리스트의 값과 같지 않을 경우라면(정렬 끝),
# 왼쪽 서브 리스트의 값을 리스트에 덮어쓰기, 그렇지 않은 경우라면 오른쪽 서브 리스트의 값 할당
mergeSort(a)
print('')
print(a) # 정렬 후 리스트
#출력
[3, 2, 5, 9, 6]
[2, 3, 5, 6, 9]
6. 쉘정렬
쉘정렬은 불안정 정렬이며 삽입 정렬을 개선한 확장판이라고 할 수 있다. 적은량의 데이터에서 빠른 속도를 나타내는 삽입 정렬의 장점을 살려, 일정한 방법으로 간격을 나누고 그 간격별로 삽입정렬을 실행하는 방법이다. 간격별 정렬을 마치면, 다시 반복 작업을 진행한다. 이 간격에 따라 시간복잡도가 천차만별이다. 최대 O(n^2)의 시간복잡도를 갖는다. 다른 간격 정의를 사용한다 하더라도 현재까지 알려진 바로는 O(nlog2n)이 최선이다.
import random # random 메소드 사용을 위해 import
a = random.sample(range(1, 10), 5) # 1<= x < 10의 난수 5개 리스트로 생성
print(a) # 정렬 전 리스트
print('')
def InsertionSort(x, start, gap): # 삽입정렬 구현
for target in range(start+gap, len(x), gap): # (시작인덱스+차이, 리스트 크기만큼 반복, 차이까지)
val = x[target] # 리스트의 값
i = target # 인덱스 저장
while i > start: # 증감 값 보다 인덱스가 크다면 반복
if x[i-gap] > val: # 리스트의 비교 인덱스 값 보다 크다면
x[i] = x[i-gap] # 해당 인덱스 값 할당
else: # 리스트의 비교 인덱스 값 보다 작다면
break # 반복 중지
i -= gap # 중간 값만큼 빼주기
x[i] = val # 해당 값 삽입
def shellSort(x): #
gap = len(x) // 2 # 리스트를 2로 나눈 몫 (중간 값) 취함
while gap > 0: #
for start in range(gap): # 중간 값의 크기만큼 반복
InsertionSort(x, start, gap) # 삽입정렬 메소드 호출 (리스트, 증감 값, 중간 값)
gap = gap // 2 # 리스트를 2로 나눈 몫 (중간 값) 취함 (반으로 줄여나간다.)
shellSort(a)
print('')
print(a) # 정렬 후 리스트
#출력
[8, 4, 2, 3, 7]
[2, 3, 4, 7, 8]
7. 기수정렬
시간 복잡도가 O(d(n+k))으로 선형 시간에 수행 할 수 있는 정렬 알고리즘이다. (d: 자리 수를 의미, d 자리수 숫자 n개가 주어졌을 때, 각 자리 수에서 최대 k값을 가질 수 있다.) MSB->LSB(큰 자리 수부터 정렬), LSB->MSB(작은 자리수부터 정렬)하는 2가지 방식이 있다. 최대 O(dn)의 시간복잡도를 갖는다.
import random # random 메소드 사용을 위해 import
a = random.sample(range(1,10,5) # 1<= x < 10의 난수 5개 리스트로 생성
print(a) # 정렬 전 리스트
print('')
def radixSort(a):
isSort = False # 정렬 완료시 True
index = 1 # 시작 인덱스
while not isSort: # 정렬이 되지 않았다면 반복
isSort = True # 정렬 상태 확인 변수
sortList = [list()for _ in range(10)] # 빈 리스트 선언
for num in a: # 리스트의 크기만큼 반복
number = (int)(num/index)%10 # 자리 수를 기준으로 정렬하기 위한 변수 할당
sortList[number].append(num) # 자리 수를 기준으로 리스트에 인덱스 선언
if isSort and number > 0: # 정렬 되지 않았다면 && 자리 수 변수가 0보다 크다면
isSort = False # 정렬 안 됨~
i = 0 # 인덱스 증가용 변수 선언
for number1 in sortList: # 정렬 리스트 크기만큼 반복
for num in number1: # 증감 값의 크기만큼 반복
a[i] = num # 리스트에 인덱스 값 넣기
i += 1 # 인덱스 증가
index *= 10 # 자리 수 증가
radixSort(a)
print('')
print(a) # 정렬 후 리스트
#출력
[8, 1, 4, 2, 5]
[1, 2, 4, 5, 8]
특별한 경우가 아니라면 내장 Python에서 제공하는 내장 메소드를 통해 아주 편리하게 정렬을 진행할 수 있다.
파이썬 내장 정렬 메소드
import random # random 메소드 사용을 위해 import
a = random.sample(range(1, 10), 5) # 1<= x < 10의 난수 5개 리스트로 생성
print(a) # 정렬 전 리스트 출력
a.sort() # 오름차순 정렬
print(a) # 정렬 후 리스트 출력
a.sort(reverse=True) # 내림차순 정렬
print(a) # 정렬 후 출력
print(sorted(a)) # sorted 함수 사용 정렬
print(sorted("This is a Moon's world".split(), key=str.lower)) # sorted 함수를 이용한 키 값 기준 정렬
b= [('abc','A',3), ('bcd','B',1), ('cde','C',15)] # 불특정 tuple을 갖는 리스트 생성
print(sorted(b, key=lambda b: b[2])) # tuple의 2번 째 요소를 가지고 정렬
# 출력
[4, 5, 8, 2, 6]
[2, 4, 5, 6, 8]
[8, 6, 5, 4, 2]
[2, 4, 5, 6, 8]
['a', 'is', "Moon's", 'This', 'world']
[('bcd', 'B', 1), ('abc', 'A', 3), ('cde', 'C', 15)]
간단하게 정렬알고리즘을 정리해보자면 데이터 양이 많아지거나저렇게 많은량의 정렬이 필요할까?복잡한 데이터 조합을 정렬할 경우에 최악의 경우 O(n^2)의 시간 복잡도를 나타내는 알고리즘은 되도록 지양하고 nlogn수준의 정렬 알고리즘을 권장한다고 할 수 있겠다.
수 많은 알고리즘 중에 정렬 알고리즘은 중요하기도 하고 기초 중에 기초라고 한다.기초라고 이게? 정렬과는 약간 다른 얘기지만, 일반적으로 코드를 작성할 때 반복문을 사용할 일이 부지기수이다. 이럴 때, 수학적 접근법?을 사용하면 빠른 속도의 효과를 낼 수 있다.
이를 테면, 1부터 n까지 더하는 코드는 nx(n+1)/2, min부터 max까지 더하는 코드는 (max+min)x(max-min+1)/2 같은 식이다.
정렬 알고리즘과 더불어 수학적 계산 방법은 항상 열심히 계산하는 우리의 CPU를 위해 다양하게 응용 해보도록 노력해야겠다. 다음 목표는 완벽한 이해를 위해 재귀함수 호출 부분을 반복문만을 이용해서 구현 하는걸로~
- 오타나 잘못된 부분을 지적 해주시면 감사히 생각하고 수정토록 하겠습니다 :)
- 시간 복잡도 참고
- Big-O 표기법 참고
- 정렬 알고리즘 참고
- 정렬 알고리즘 참고
- 정렬 알고리즘 참고
- 정렬 알고리즘 참고
- 정렬 알고리즘 참고
Subscribe via RSS