파이썬 크롤링 테스트
by Seongjae Moon
저번 포스팅에 이어서 파이썬 기초부터 웹 크롤러 개발 다섯 번째 포스팅을 진행해보자. 이번 포스팅에선 HTML 기초 문법 및 크롤링을 위한 HTML 분석 방법에 대해 알아보고, 라이브러리를 이용한 실제 테스트 크롤링 코드 작성에 대해 정리해보자. 테스트 코딩용 파이썬 에디터는 Atom과 script 패키지를 이용해서 작성하였고, Python 3.6.4 버전을 사용했다.
HTML과 크롬 개발자 도구.
우선 HTML에 대해서 알아보자. HTML은 마크업 언어로서, 이미 정해진 문법으로 코드를 작성하면 웹에 그 내용이 보여지게 되는 웹 언어 라고 할 수 있다. 참고로 Github pages는 마크다운 문법으로 글이 작성되는데, 마크다운은 간단히 말해 이러한 마크업 언어를 조금 더 쓰기 쉽게 만든 언어라고 할 수 있다. 때문에 글을 작성할 때 HTML 문법을 이용해 작성해도 잘 적용되는 것을 확인할 수 있다. 아무튼, 이벤트 처리를 담당하는 javascript나 jquery 등의 내용은 여기서 필요하지 않으니 다음 기회에 다루는 것으로 하고, HTML 문법에 대해 알아보자. (크롤링을 위한 다양한 정보는 크롬 브라우저를 이용해 분석하게 될테니 먼저 크롬을 다운로드한다.)
일단 아래와 같은 간단한 html 확장자를 가진 파일이 있다고 가정해보자. id 속성이 board인 div 태그와 class 속성이 table인 table 태그로 구성되어 있는 것을 확인할 수 있다.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Web Scraping Test</title>
</head>
<body>
<div id = "board">
<h1>Hello World</h1>
<table class ="table">
<thead>
<tr>
<th>이름</th>
<th>나이</th>
</tr>
</thead>
<tbody>
<tr>
<td>Moon</td>
<td>20</td>
</tr>
</tbody>
</table>
</div>
</body>
</html>
위 코드를 Atom에서 sample.html 이라고 저장하고 script로 실행하면 아래와 같은 컨텐츠가 있는 페이지가 열리는 것을 확인할 수 있다. 20살이고 싶다..
 이제 위 테스트 코드를 개발자 도구를 이용해 확인하는 테스트를 진행해보자. 아래와 같이 내가 원하는 컨텐츠를 드래그하고 마우스 우클릭을 하면 여러가지 선택 항목이 나타나는데, 여기서 검사를 클릭한다.
이제 위 테스트 코드를 개발자 도구를 이용해 확인하는 테스트를 진행해보자. 아래와 같이 내가 원하는 컨텐츠를 드래그하고 마우스 우클릭을 하면 여러가지 선택 항목이 나타나는데, 여기서 검사를 클릭한다.
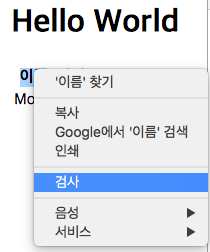 검사를 클릭하면 개발자 도구가 열리면서 아래와 같이 내가 원하는 컨텐츠가 어떤 엘리먼트에 속해있는지 확인할 수 있다.
검사를 클릭하면 개발자 도구가 열리면서 아래와 같이 내가 원하는 컨텐츠가 어떤 엘리먼트에 속해있는지 확인할 수 있다.
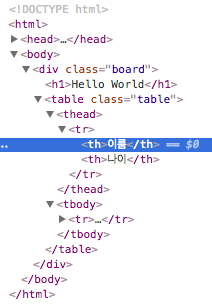 또한, 아래에서 나올 선택자 문법을 통해 정보를 추출하거나 전체적인 부모 태그 정보를 확인할 때, Copy selector 기능을 이용하면 내가 찾고자하는 엘리먼트의 접근하기 위해 거쳐야 하는 태그 정보를 한 눈에 볼 수 있어 편리하다.
또한, 아래에서 나올 선택자 문법을 통해 정보를 추출하거나 전체적인 부모 태그 정보를 확인할 때, Copy selector 기능을 이용하면 내가 찾고자하는 엘리먼트의 접근하기 위해 거쳐야 하는 태그 정보를 한 눈에 볼 수 있어 편리하다.
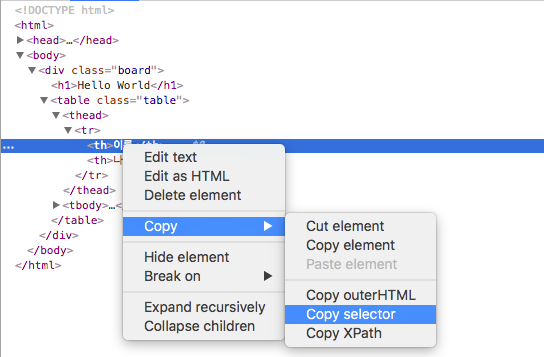
위 html 코드는 굉장히 짧고 직접 작성한 코드이기 때문에 이렇게 검사하는게 큰 의미가 없지만, 실제 크롤링 하기 원하는 사이트의 특정 컨텐츠의 html 정보를 확인하기 위해 개발자 도구는 굉장히 유용하다. 또한, 아래에 나올 네트워크 정보 확인을 위해서도 개발자 도구 사용은 필수라고 할 수 있다.
테스트 크롤링 코드 작성.
위 샘플 html 코드는 url에 많은 정보가 없어 분석하기 용이하지 않다. 때문에 실제 서비스 되고 있는 웹 사이트를 대상으로 데이터를 가져오는 크롤링 작업을 진행해보자. 여기선 팟빵 사이트의 월간 종합 순위 2018.03일자 1위부터 1000위 까지의 데이터를 크롤링한다고 가정하자. 우선 어떤 데이터를 크롤링할지 선정해야 한다. 우리 눈에 보이는 웬만한 컨텐츠는 모두 크롤링이 가능하다.(이미지도 가능하다.) 여기선, 순위와 제목, 좋아요 개수를 크롤링해보자.
HTML 분석.
먼저, 워크 플로우는 사이트에 접속해서 원하는 데이터의 엘리먼트 태그 정보와 url 정보를 분석한다. 분석이 끝나면, requests 라이브러리와 bs4 라이브러리를 사용해서 url을 통해 해당 사이트를 요청하고, 요청한 사이트 정보가 정상적으로 호출되어 200번 코드가 돌아오면 원하는 정보를 적절하게 추출하면 된다.
http://www.podbbang.com/ranking?kind=monthly&ddate=2018-03&start=1
먼저, 위 url이 우리가 분석할 팟빵 사이트 url이라고 할 수 있다. GET 방식으로 값을 표현하고 있고, 주소의 어떤 부분을 변경하면 다른 정보를 요청 받을 수 있는지 하나하나 파악해보자.
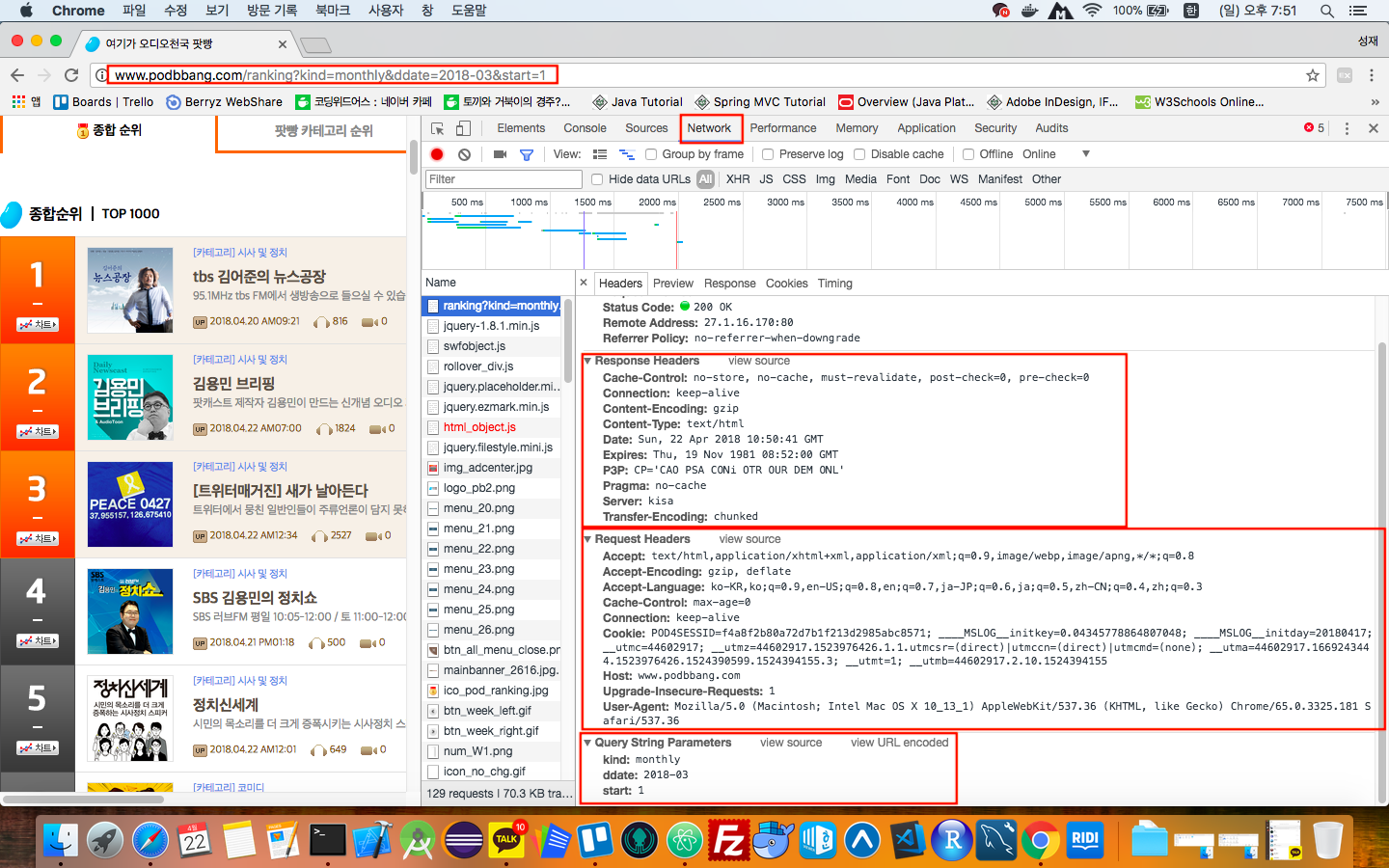 위 사진은 개발자 도구를 열고 Network 탭을 누르면 보이게 되는 화면으로, 크롤링할 때 가장 처음 확인하는 화면이다. 만약 “Recording network activity.”라는 화면이 나오면 페이지 새로고침을 해준다. 팟빵 사이트는 아래에 나올 requests 모듈의 get 함수를 이용해 사이트를 요청할 때 특별한 헤더를 함께 전송하지 않아도 정상적으로 사이트 요청이 이루어진다. 헤더 정보가 담겨있지 않으면, 300번 에러(권한 없음)를 발생시키는 사이트도 더러 있는데, 그 부분은 다음 포스팅에서 알아보도록 하고, 일단 여기서 주목할 부분은 Query String Parameter 부분으로, kind : monthly, ddate : 2018-03, start : 1라는 값을 나타내는 것을 확인할 수 있다. 이 부분만 적절하게 코드 상에서 바꿔주면 여러 페이지의 데이터를 일괄적으로 읽어오는게 가능할 것으로 짐작할 수 있다.
위 사진은 개발자 도구를 열고 Network 탭을 누르면 보이게 되는 화면으로, 크롤링할 때 가장 처음 확인하는 화면이다. 만약 “Recording network activity.”라는 화면이 나오면 페이지 새로고침을 해준다. 팟빵 사이트는 아래에 나올 requests 모듈의 get 함수를 이용해 사이트를 요청할 때 특별한 헤더를 함께 전송하지 않아도 정상적으로 사이트 요청이 이루어진다. 헤더 정보가 담겨있지 않으면, 300번 에러(권한 없음)를 발생시키는 사이트도 더러 있는데, 그 부분은 다음 포스팅에서 알아보도록 하고, 일단 여기서 주목할 부분은 Query String Parameter 부분으로, kind : monthly, ddate : 2018-03, start : 1라는 값을 나타내는 것을 확인할 수 있다. 이 부분만 적절하게 코드 상에서 바꿔주면 여러 페이지의 데이터를 일괄적으로 읽어오는게 가능할 것으로 짐작할 수 있다.
- 페이징 처리
HTML 태그를 분석하기 전에 페이징 처리라는 것에 대해 알아보자. 페이징은 시작 페이지와 다음 페이지들 간의 규칙을 찾아내고, 이 규칙에 따라 시작페이지의 값을 바꿔주어 요청할 사이트를 변경하는 것을 말한다. 직접 확인하면 알 수 있지만, 팟빵 사이트는 1, 101, 201, … ,901. 형식으로 start의 값이 변화하는 것을 알 수 있다.
이를 수식으로 표현하면 \((100 \cdot 0) + 1, (100 \cdot 1) + 1, (100 \cdot 2) + 1, ... (100 \cdot 9) + 1\)로 바꿔 쓸 수 있는데 바뀌는 부분이 100에 곱해지는 부분이니, 이 부분을 반복문 처리하면 될 것이라는 것을 직감할 수 있다.
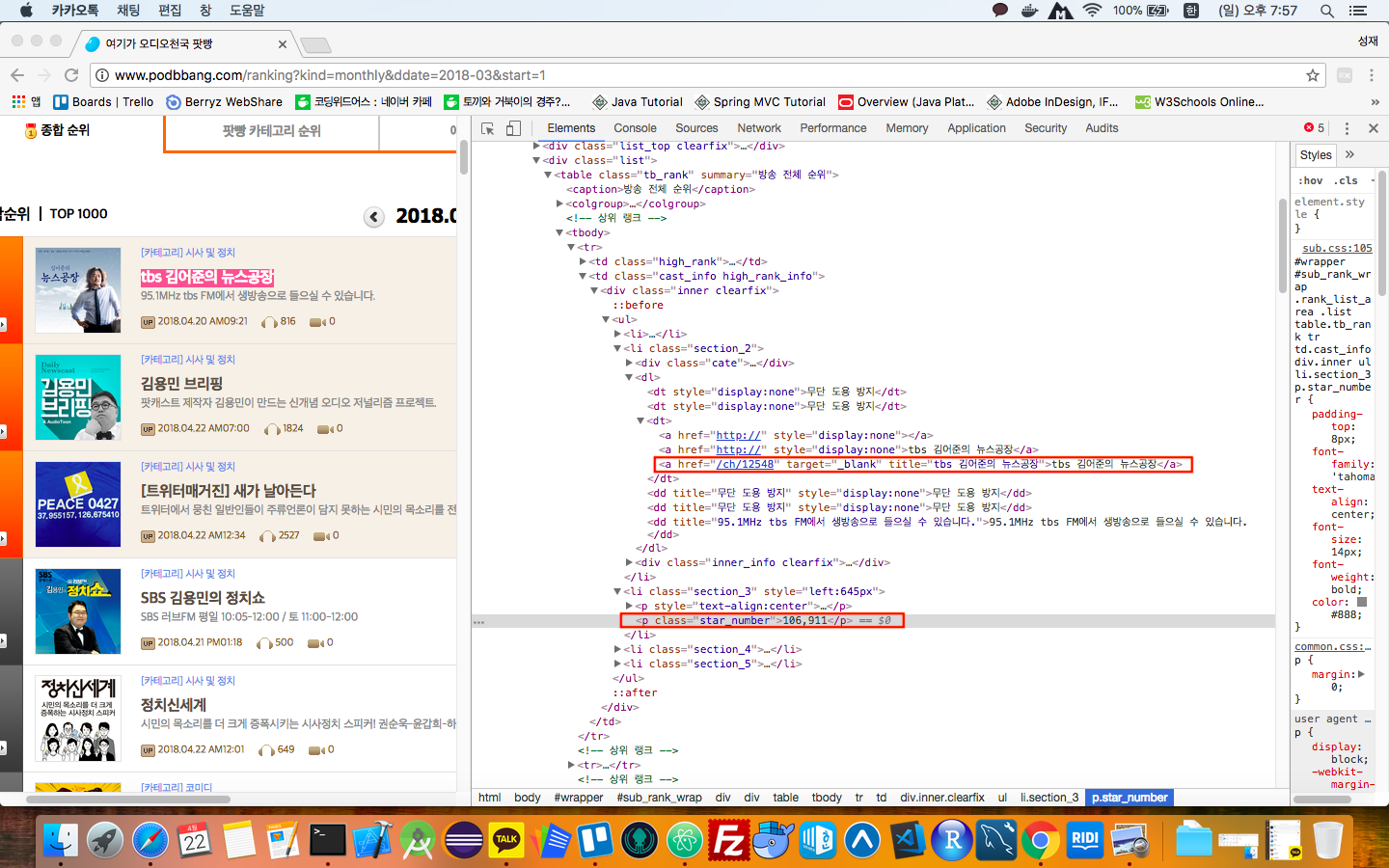 url 분석이 끝났으니 실제 어떤 태그 정보를 가져와야 하는지 확인하는 작업이 필요하다. 앞서 언급한 개발자 도구의 검사 기능과 Copy selector 기능을 이용해 태그의 접근하기 위한 정보를 확인한다.
url 분석이 끝났으니 실제 어떤 태그 정보를 가져와야 하는지 확인하는 작업이 필요하다. 앞서 언급한 개발자 도구의 검사 기능과 Copy selector 기능을 이용해 태그의 접근하기 위한 정보를 확인한다.
-
제목 : sub_rank_wrap > div.rank_list_area > div.list > table > tbody > tr:nth-child(1) > td.cast_info.high_rank_info > div > ul > li.section_2 > dl > dt:nth-child(3) > a:nth-child(3)
-
좋아요 : sub_rank_wrap > div.rank_list_area > div.list > table > tbody > tr:nth-child(1) > td.cast_info.high_rank_info > div > ul > li.section_3 > p.star_number
Copy selector를 이용해서 접근하기 위한 방법을 확인한 후, 태그 중에 우리가 원하는 정보를 감싸고 있는 가까운 부모 태그를 확인하다. 여기선 하나의 table 태그에 td 태그로 원하는 값이 들어 있는 것을 알 수 있다. 아직 순위 정보에 대한 언급이 없는데, 순위 정보는 직접 데이터를 긁어와도 되지만, 하나의 테이블의 tr의 총개수를 계산하면 된다. 때문에 코드 상에서 해결할 수 있는 부분이므로 여기선 따로 크롤링하지 않는다.
크롤링 코드 작성.
위에서 url과 html에 대한 분석이 끝났으니 이제 실제 코드로 url을 요청하고 데이터를 추출하는 작업을 진행하면 된다. 전체 코드는 아래와 같다.
# 외부 라이브러리 import
from bs4 import BeautifulSoup
import requests
import sys
import io
# 아톰에서 한글 에러 방지를 위한 선언.
sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding = 'utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.detach(), encoding = 'utf-8')
# 제목과 좋아요 수를 반환할 함수 선언.
def get_inner(td_list):
title = td_list[3].split('title="')[1].split('">')[0] # 제목을 얻어온다.
star = td_list[3].split('star_number">')[1].split('</p>')[0] # 좋아요 개수를 얻어온다.
return title, star
rank = 1 # 순위 계산을 위한 변수 선언.
for page in range(0, 10): # start - 1 ~ 901까지 반복.
url = "http://www.podbbang.com/ranking?kind=monthly&ddate=2018-03&start={}" # 크롤링할 url의 start 값을 변경하기 위해 포멧으로 선언.
req = requests.get(url.format(str((100 * page) + 1))) # 사이트 요청.
# BeautifulSoup 함수를 이용해 html 문서 자체를 받아온다. 팟빵 사이트는 인코딩 문제 때문에 한글이 깨지므로, 데이터를 받아올 때 utf-8로 디코딩하는 작업이 필요하다.
bs = BeautifulSoup(req.content.decode('utf-8', 'replace'), 'html.parser')
# 클래스 속성이 tb_rank인 테이블 태그 (바로 tr 태그를 가져와도 된다.).
# find 메서드는 id, class, html 요소를 통해 특정 태그 엘리먼트의 대한 값을 bs 객체로 반환한다.
table = bs.find('table', class_ = 'tb_rank')
# 가져온 테이블 태그 중에 모든 tr_tag 가져오기. - 하나의 행.
# find_all 메서드는 파라미터를 구분자로 하여 리스트 형식으로 값을 반환한다.
tr = table.find_all('tr')
for idx in range(0, len(tr)): # tr 크기만큼 반복.
td_list = str(tr[idx]).split('td') # 모든 td-tag 가져오기. - 하나의 열.
title, star = get_inner(td_list)
print(rank, title, star) # 값이 잘 추출되는지 확인한다.
# 하나의 페이지의 크롤링이 끝났을 경우 다음 페이지의 시작 rank로 rank 값을 변경해준다. (팟빵 사이트는 종료 순위가 모두 다르기 때문에 처리가 필요.)
if idx == (len(tr)-1):
rank = (100 * (page + 1)) + 1
else:
rank += 1
전체 코드 내용 중 제목과 좋아요 갯수를 얻어오는 부분에 대해서 알아보자. 사실, 한 번에 데이터를 추출할 수 있으면 좋지만 테스트 코드를 작성하고 값이 잘 추출되는지 확인하는 몇 번의 삽질 작업이 필요하다.
# 하나의 열의 여러개 td로 구성된 데이터 중 네번째 td에 제목이 포함되어 있다.
# 그 중, title="로 구분하여 리스트를 만들면 인덱스 1의 값이 제목을 포함하고 있다.
# 그 중, ">로 구분하여 리스트를 만들면 인덱스 0의 값이 제목을 나타낸다.
title = td_list[3].split('title="')[1].split('">')[0]
# 하나의 열의 여러개 td로 구성된 데이터 중 네번째 td에 좋아요가 포함되어 있다.
# 그 중, star_number">로 구분하여 리스트를 만들면 인덱스 1의 값이 좋아요 수를 포함하고 있다.
# 그 중, </p>로 구분하여 리스트를 만들면 인덱스 0의 값이 좋아요 수를 나타낸다.
star = td_list[3].split('star_number">')[1].split('</p>')[0]
엑셀 파일로 저장.
위와 같이 코드를 작성하고 실행하면, 데이터가 아래와 같이 아톰 콘솔에 잘 찍히는 것을 확인할 수 있다.
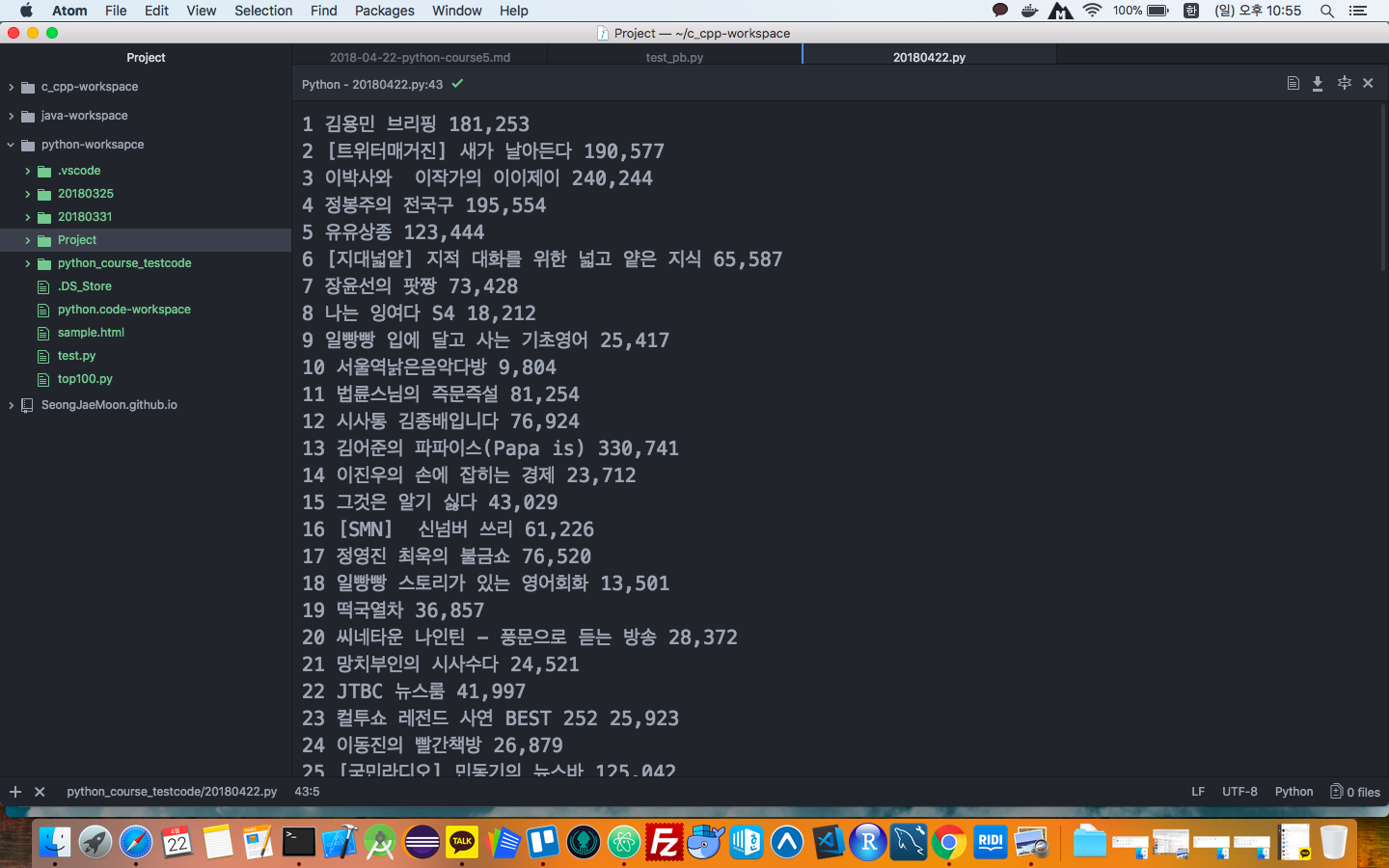
하지만, 데이터를 크롤링하고 크롤링한 데이터를 분석하기 위해서 추출한 데이터를 데이터베이스에 저장하거나 다른 포멧의 파일 형태로 만들어 저장하는 것이 용이할 수 있다. 우선 이번 포스팅에선 크롤링 데이터를 엑셀 파일 형태로 만드는 법에 대해서 알아보자.
크롤링 데이터를 엑셀 파일로 변환하기 위해 openpyxl 라이브러리를 활용해야 하기 때문에 pip를 이용해 다운로드 받는다.
pip3 install openpyxl
openpyxl의 함수를 이용해 엑셀 파일을 읽고 쓸 수 있는데, 여기선 기존의 빈 엑셀 파일을 원하는 경로에 미리 생성해놓고, 이 파일을 불러와 파일을 새로 쓰는 것에 대해 알아보자.
from bs4 import BeautifulSoup
import requests
import sys
import io
from openpyxl import load_workbook
# 아톰에서 한글 에러 방지를 위한 선언.
sys.stdout = io.TextIOWrapper(sys.stdout.detach(), encoding = 'utf-8')
sys.stderr = io.TextIOWrapper(sys.stderr.detach(), encoding = 'utf-8')
# 제목과 좋아요 수를 반환할 함수 선언.
def get_inner(td_list):
title = td_list[3].split('title="')[1].split('">')[0] # 제목을 얻어온다.
star = td_list[3].split('star_number">')[1].split('</p>')[0] # 좋아요 개수를 얻어온다.
return title, star
rank = 1 # 순위 계산을 위한 변수 선언.
total = 1 # 자동 증가 변수(row 증가용).
for page in range(0, 10): # start - 1 ~ 901까지 반복.
url = "http://www.podbbang.com/ranking?kind=monthly&ddate=2018-03&start={}" # 크롤링할 url의 start 값을 변경하기 위해 포멧으로 선언.
req = requests.get(url.format(str((100 * page) + 1))) # 사이트 요청.
# BeautifulSoup 함수를 이용해 html 문서 자체를 받아온다. 팟빵 사이트는 인코딩 문제 때문에 한글이 깨지므로, 데이터를 받아올 때 utf-8로 디코딩하는 작업이 필요하다.
bs = BeautifulSoup(req.content.decode('utf-8', 'replace'), 'html.parser')
# 클래스 속성이 tb_rank인 테이블 태그 (바로 tr 태그를 가져와도 된다.).
# find 메서드는 id, class, html 요소를 통해 특정 태그 엘리먼트의 대한 값을 bs 객체로 반환한다.
table = bs.find('table', class_ = 'tb_rank')
# 가져온 테이블 태그 중에 모든 tr_tag 가져오기. - 하나의 행.
# find_all 메서드는 파라미터를 구분자로 하여 리스트 형식으로 값을 반환한다.
tr = table.find_all('tr')
try:
wb = load_workbook('/Users/moonseongjae/testpb.xlsx') # 저장된 엑셀파일을 불러온다.
ws = wb.create_sheet(title = '2018-03-pb') # 새로운 시트를 만든다.
# 제목 작성.
ws['A1'] = '순위'
ws['B1'] = '제목'
ws['C1'] = '좋아요'
for idx in range(0, len(tr)): # tr 크기만큼 반복.
td_list = str(tr[idx]).split('td') # 모든 td-tag 가져오기. - 하나의 열.
title, star = get_inner(td_list)
# 제목을 제외하고 row의 값에 각각 원하는 값을 할당.
ws['A' + str(1 + total)] = rank
ws['B' + str(1 + total)] = title
ws['C' + str(1 + total)] = star
# total 증가.
total += 1
# 하나의 페이지의 크롤링이 끝났을 경우 다음 페이지의 시작 rank로 rank 값을 변경해준다. (팟빵 사이트는 종료 순위가 모두 다르기 때문에 처리가 필요.)
if idx == (len(tr)-1):
rank = (100 * (page + 1)) + 1
else:
rank += 1
wb.save('/Users/moonseongjae/testpb.xlsx') # 엑셀 파일에 저장한다.
finally:
wb.close() # wb 객체 무조건 닫기.
위와 같이 코드를 작성하고 실행하면 아래 사진과 같이 “2018-03-pb” 이름을 가진 새로운 시트가 만들어지고 크롤링한 데이터가 하나씩 삽입된 것을 확인할 수 있다. openpyxl 라이브러리엔 다양한 기능을 제공하는 함수가 존재하는데, 새삼 21세기임을 실감한다..
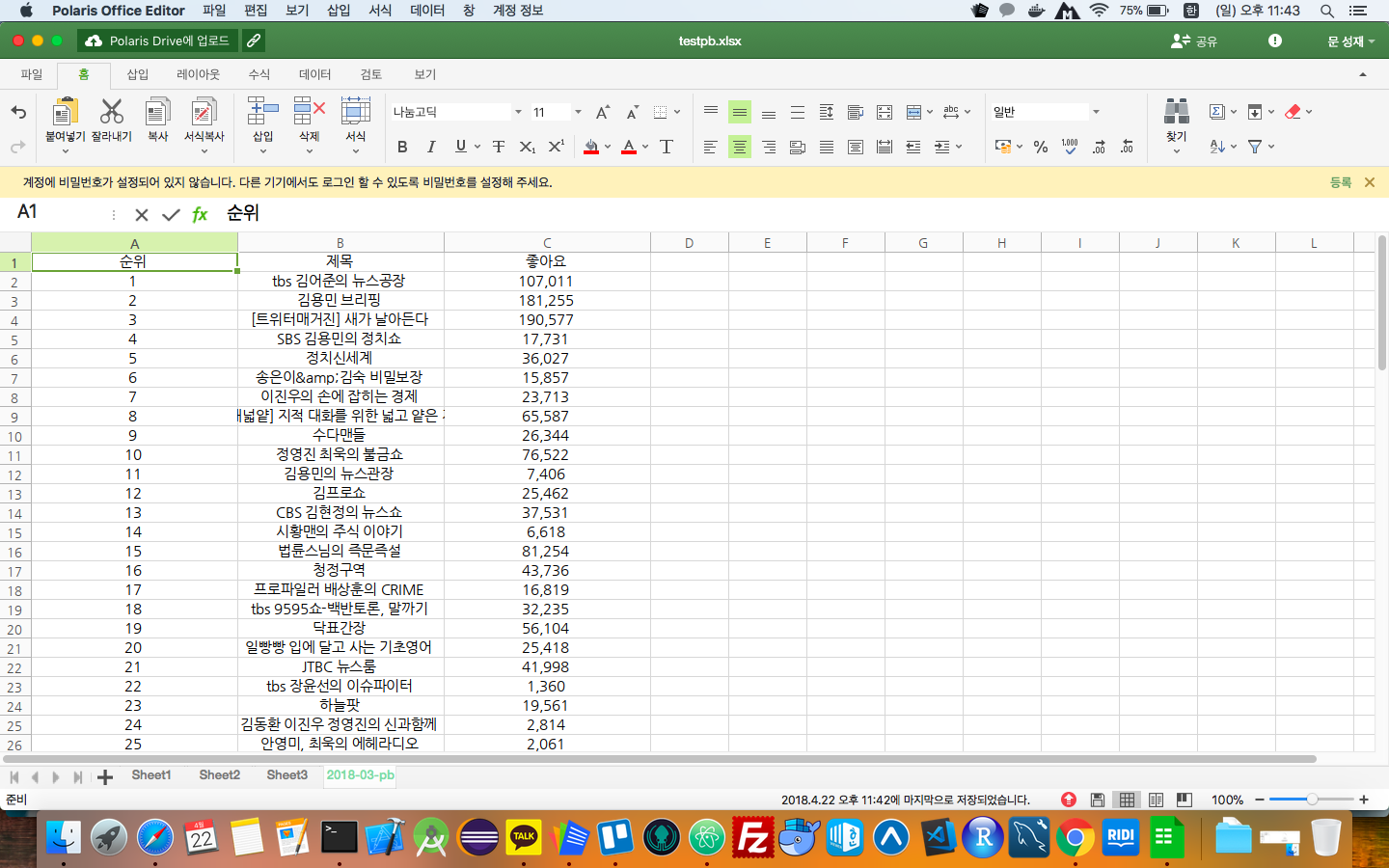
이렇게 간단한? 크롤링 테스트 코드를 정리했다. 다음 포스팅에선 크롤링 하기 조금 더 어려운 사이트를 크롤링하는 방법과 크롤링을 자동화해서 MySQL DB와 Firebase 클라우드 스토리지에 저장하는 방법에 대해 정리해보는 걸로~
-
오타나 잘못된 부분을 지적해주시면 감사히 생각하고 수정토록 하겠습니다 :)
- 참고 사이트
- The Hitchhiker’s Guide to python
- freeCodeCamp guide python
- The Python tutorial
- 예제로 배우는 Python 프로그래밍
Subscribe via RSS