파이썬 Selenium 크롤링
by Seongjae Moon
저번 포스팅에 이어서 파이썬 기초부터 웹 크롤러 개발 여섯 번째 포스팅을 진행해보자. 이번 포스팅에선 Selenium 라이브러리를 이용해 크롬 브라우저 조작을 통한 특정 웹 페이지의 데이터를 크롤링하고, MySQL DB에 저장하는 부분에 대해 알아보자. 테스트 코딩용 파이썬 에디터는 Visual Studio Code를 이용해서 작성하였고, Python 3.6.4 버전을 사용했다. (파이썬 코드 테스트용 에디터를 아톰에서 VS code로 변경한 이유엔 여러가지가 있지만, 트렌디 함을 따라가는게 역시 가장 중요했다..?)
주의) 공격적이고 무분별한 크롤링과 악의적인 이유의 크롤링은 무조건적으로 지양되어야 합니다.
테스트 크롤링 코드 작성.
먼저, 이번에 크롤링할 웹 사이트는 파이썬과 장고 프레임워크를 이용해 개발 되었다고 하는 아주 잘 알려진 인★그램 사이트이다. 아래 url이 우리가 selenium을 통해 크롤링할 웹 사이트라고 할 수 있다.
https://www.instagram.com/explore/tags/python/
크롬 드라이버 다운로드.
우선 Selenium 라이브러리를 이용해 크롬 브라우저를 조작하기 위해 여기에서 크롬 드라이버를 다운로드하아야 한다. 사이트에 접속해서 원하는 버전을 다운로드하고 적절한 위치에 저장한다. (여기선 가장 최신 버전인 2.38을 이용했다.) 아울러, Firefox, Safari 등 다른 다양한 브라우저 드라이버를 다운로드하고 사용해도 된다. 일부 글에선 Firefox 브라우저를 이용한 방법이 가장 안정적으로 동작한다고 한다.
Selenium, konlpy 라이브러리 다운로드.
다음은 오늘의 주인공 selenium(셀레니움) 라이브러리를 pip로 다운로드 받는다.
pip3 install selenium
저번 포스팅에서 알아봤듯이 크롤링을 위해서는 사이트에 접속해서 여러 가지 정보를 분석해야 한다. 사실, HTML 구조를 분석하는 것도 중요하지만 요청해야 하는 Parameter라던지, Header 정보 등 요청 시 함께 전송해야 하는 여러 가지 정보들이 존재한다. 이러한 이유로 urllib나 requests 라이브러리로 단순히 GET, POST 요청을 하면 웬만한 사이트는 303 접근 불가 에러를 띄운다. 이 부분은 따로 포스팅을 할애해서 정리하는 것으로 하고, Selenium 이라는 라이브러리를 이용하면 브라우저를 직접 조작하는 것이므로 이러한 것을 염두하지 않아도 된다는 것 정도만 인지하면 될 것 같다.
다음은 konlpy(코엔엘파이)라는 라이브러리를 다운로드 한다. konlypy는 한국어 정보 분석용 파이썬 라이브러리를 하나로 묶어서 편하게 사용할 수 있도록 만든 라이브러리이다. 언어를 분석하기 위한 라이브러리는 여러 가지가 있겠지만, 우리는 konlpy 라이브러리와 정규표현식을 통해 모든 걸 해결하길? 원하므로 konlpy 라이브러리만 마찬가지로 pip를 이용해서 다운로드한다.
pip3 install konlpy
이제 준비가 끝났으니, 본격적으로 HTML 분석과 크롤링 코드 작성을 진행해보자.
HTML 분석.
먼저 크롬 브라우저를 열고 위 사이트에 접속하고 아무 사진이나 선택해서 마우스 우클릭을 눌러 검사 기능을 실행한다. 그럼 아래와 같은 화면이 보여지게 된다.
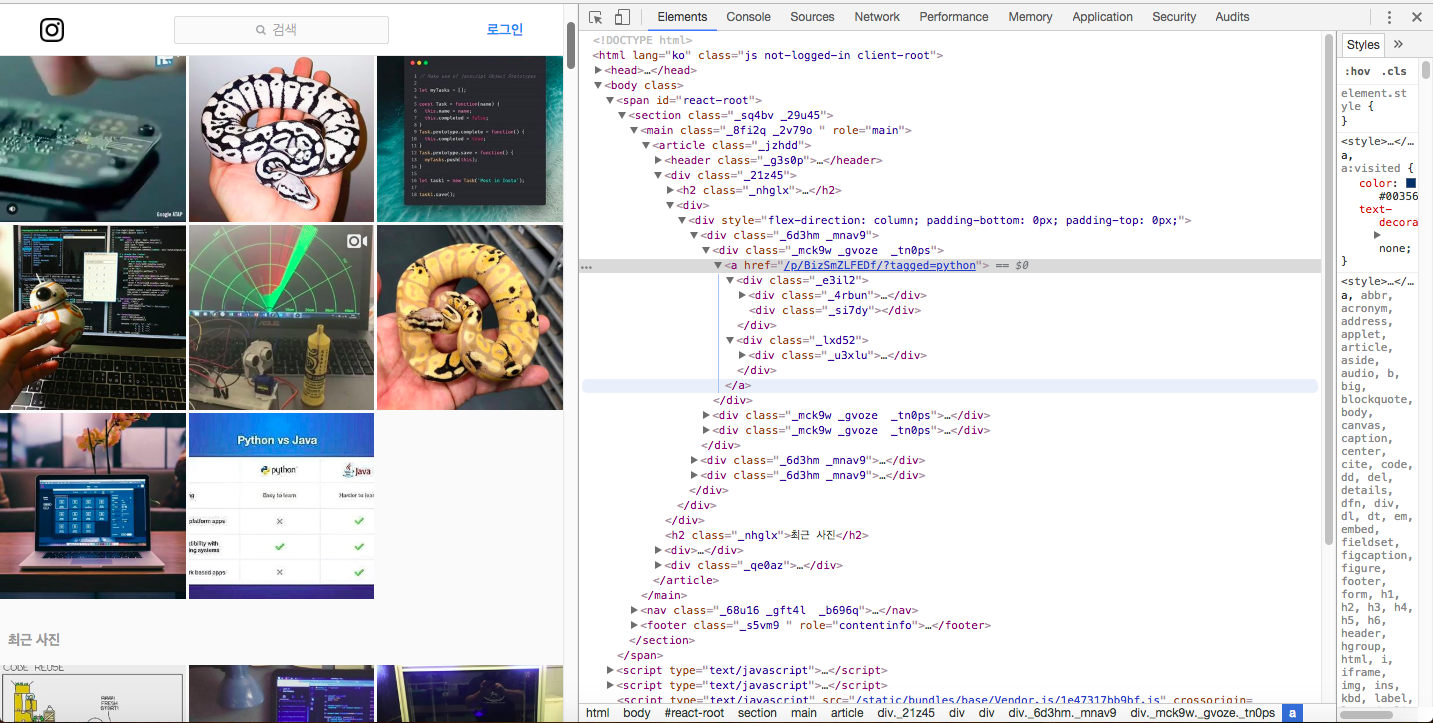
일반적으로 웹 상에 나타나는 모든 정보는 크롤링이 가능하다고 보면 된다. 여기서 우리는 많은 데이터 중 전체 게시물 수와 가장 많이 나온 상위 15개의 해시태그에 대한 정보만을 추출한다고 가정 하자.
먼저, 총 게시물 수는 _fd86t를 클래스 속성 값으로 갖는 span 태그의 값임을 확인할 수 있다. 다음으로, 해시태그에 대한 정보를 가져오는 방법은 여러가지가 있을 수 있지만, KL4Bh를 클래스 속성 값으로 갖는 div 태그 자식 중 img 태그의 alt 속성의 값이 작성자의 글과 해시태그 목록을 가지고 있는 것을 확인할 수 있다. 이 것을 각각 CSS 선택자 문법으로 표현하면 아래와 같다.
/* span 태그 찾기 */
span._fd86t
/* img 태그 찾기 */
div.KL4Bh > img
이제 위와 같은 기본 정보를 가지고 파이썬 코드를 작성해보자.
크롤링 코드 작성.
Selenium
우선 selenium 라이브러리를 이용해 크롤링을 진행하기 위해선 selenium 라이브러리에 속한 DOM 요소를 선택하는 기본적인 메서드 들에 대해서 알아야 한다. 여기선 우리가 코드 작성을 위해 필요로 하는 몇 가지 메서드만 살펴보자.
| 항목 | 설명 |
|---|---|
| find_element_by_class_name | 클래스 이름이 name에 해당하는 요소를 하나 추출 |
| find_elements_by_css_selector | CSS 선택자로 요소를 여러개 추출 |
| find_element_by_tag_name | 태그 이름이 name에 해당하는 요소를 하나 추출 |
| get_attribute | 요소의 속성 중 name에 해당하는 속성의 값을 추출 |
| send_keys(value) | value에 해당하는 키를 입력 |
| text | 요소 내부의 글자 |
selenium 라이브러리는 브라우저 조작과 관련된 굉장히 다양한 메서드들을 제공하는데, 더 자세한 selenium 메서드에 대한 정보는 여기를 참고.
파이썬 코드 작성
import time
# 해시태그를 분석하기 위한 Twitter 모듈
from konlpy.tag import Twitter
# 크롬 브라우저 조작을 위한 모듈
from selenium import webdriver
# 페이지 스크롤링을 위한 모듈
from selenium.webdriver.common.keys import Keys
# 크롤링할 url 주소
url = "https://www.instagram.com/explore/tags/python/"
# 다운로드 받은 driver 주소
DRIVER_DIR = '/path/to/chromedriver'
# 크롬 드라이버를 이용해 임의로 크롬 브라우저를 실행시켜 조작한다.
driver = webdriver.Chrome(DRIVER_DIR)
# 암묵적으로 웹 자원을 (최대) 5초 기다리기
driver.implicitly_wait(5)
# 크롬 브라우저가 실행되며 해당 url로 이동한다.
driver.get(url)
# 총 게시물 수를 클래스 이름으로 찾기
totalCount = driver.find_element_by_class_name('_fd86t').text
print("총 게시물:", totalCount)
# body 태그를 태그 이름으로 찾기
elem = driver.find_element_by_tag_name("body")
# alt 속성의 값을 담을 빈 리스트 선언
alt_list = []
# 페이지 스크롤을 위해 임시 변수 선언
pagedowns = 1
# 스크롤을 20번 진행한다.
while pagedowns < 20:
# PAGE_DOWN(스크롤)에 따라서 결과 값이 달라진다.
# 기본적으로 브라우저 조작을 통해 값을 얻어올 때는 실제 브라우저에 보이는 부분이어야 요소를 찾거나 특정 이벤트를 발생시킬 수 있다.
elem.send_keys(Keys.PAGE_DOWN)
# 페이지 스크롤 타이밍을 맞추기 위해 sleep
time.sleep(1)
# 브라우저에 보이는 모든 img 태그를 css 선택자 문법으로 찾는다.
img = driver.find_elements_by_css_selector('div.KL4Bh > img')
# 위에서 선언한 alt_list 리스트에 alt 속성의 값을 할당한다.
for i in img:
alt_list.append(i.get_attribute('alt'))
pagedowns += 1
# 값의 중복을 방지를 리스트 set으로 변환후 리스트로 재할당
alt_list = list(set(alt_list))
# 키:해시태그, 값:횟수 형식으로 저장하기 위한 빈 딕셔너리 선언
dict_data = {}
# alt 속성의 값인 제목과 해시태그 중 해시태그 만을 가져오기 위한 Tiwitter 객체 생성
tw = Twitter()
# alt_list에 담긴 값의 크기만큼 반복한다.
for alt in alt_list:
# pos 메서드를 통해 alt 속성의 모든 해시태그의 값을 (값, 품사) 형태의 튜플을 요소로 갖는 리스트로 반환한다.
temp = tw.pos(alt, norm = True)
# 리스트의 크기만큼 반복한다.
for data in temp:
# 품사가 만약 해시태그이면
if data[1] == "Hashtag":
# 결과 값을 저장할 딕셔너리에 값이 있는지 확인하고 없다면 새로이 키를 추가하고 0, 있다면 기존 키에 1을 더해준다.
if not (data[0] in dict_data):
dict_data[data[0]] = 0
dict_data[data[0]] += 1
# 딕셔너리를 횟수를 가지고 내림차순으로 정렬한다.
keys = sorted(dict_data.items(), key = lambda x:x[1], reverse = True)
# 1~15위 까지의 키:값을 출력한다.
for k, v in keys[:15]:
print("{}({})".format(k, v))
# 드라이버를 종료한다.
driver.close()
위의 코드를 실행하면 새로운 크롬 브라우저가 열리며 “Chrome이 자동화된 소프트웨어에 의해 제어되고 있습니다.”라는 문구와 함께 작성된 url 페이지가 열린 것을 확인 할 수 있다. PAGE_DOWN을 실행했기 때문에 자동으로 스크롤링 또한 잘 이루어지는 것을 확인할 수 있다.
코드가 모두 실행되고 나면 VS code 터미널에 아래와 같은 화면이 나온 것을 확인하고 값이 잘 불러와진 것을 알 수 있다.

위 결과로 인★그램에서 파이썬을 태그할 땐 자바스크립트와 프로그래밍을 함께 많이 태그 한다는 것을 알 수 있다?
MySQL DB에 저장.
사실 훨씬 더 많은 해시태그가 존재하고, 전체 게시물이 백사십만 개가 넘어가는 것을 미루어 보았을 때 가장 많이 나온 1~15위까지라고 하기엔 무리 감이 있다. 무리 데스네! 데이터는 쌓이면 쌓일수록 그 가치가 드러나는 법! 그런 의미에서 MySQL 데이터베이스에 한 번 저장해보도록 하자.
pymysql
먼저 MySQL과 파이썬 코드를 연동하기 위해선 MySQL 관련 라이브러리가 필요하다. 마찬가지로 여러 가지 라이브러리가 존재하는데, 우리는 여기서 pymysql 라이브러리를 이용해보자.
pip3 install pymysql
DB 준비
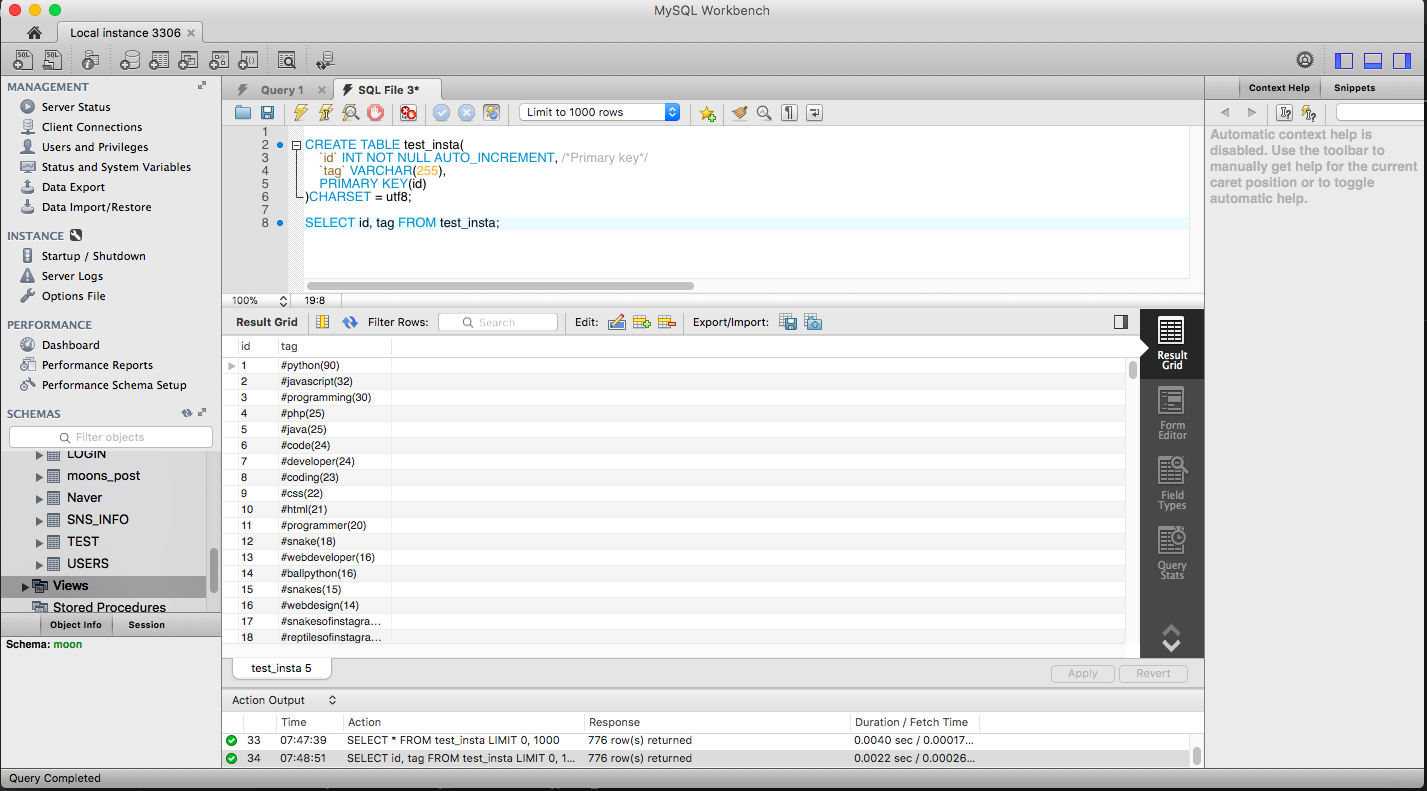
먼저, 데이터를 저장할 MySQL에 test_insta라는 테이블을 준비한다.
CREATE TABLE test_insta(
`id` INT NOT NULL AUTO_INCREMENT, /*Primary key*/
`tag` VARCHAR(255),
PRIMARY KEY(id)
)CHARSET = utf8;
굉장히 간단한 DDL문 임을 알 수 있다. 이제 파이썬 코드를 살펴보자.
파이썬 코드 작성.
우선, MySQL 데이터베이스와 연결 관리 및 DML 문을 이용하기 위해 DBConnect라는 클래스를 정의하고 db_connet.py라는 이름으로 저장하자.
import pymysql
# 클래스 선언
class DBConnect:
# 생성자 선언
def __init__(self):
# MySQL DB와 연결을 위한 connect 인스턴스를 선언
self.conn = pymysql.connect(host='localhost', user='root', password='root', db='moon', charset='utf8')
# 파이썬에서 쿼리를 사용하고 저장하기 위한 cursor 인스턴스 선언
self.curs = self.conn.cursor(pymysql.cursors.DictCursor)
# 간단한 insert 메서드 정의
def insert(self, tag_dict):
try:
# insert 쿼리 작성
sql = """insert into test_insta (tag)
values (%s)"""
for k, v in tag_dict:
# insert 쿼리를 실행한다.
self.curs.execute(sql, "{}({})".format(k, v))
# DML문 완료 후 커밋
self.conn.commit()
except Exception as e:
print(e)
finally:
# 커넥트 인스턴스를 닫아준다.
self.conn.close()
원래 코드에서 정의한 모듈을 불러와 사용하기 위해선 단 세 줄만 추가해주면 된다.
from db_connect import DBConnect
# ...중략
# 객체 생성 및 insert 메서드 호출
db = DBConnect()
db.insert(keys[:15])
이제 SELECT 쿼리를 날려보면, 아주 잘 저장된 것을 확인 할 수 있다. 얄루!
우리가 살펴본 이와 같은 방법은 내가 코드를 계속해서 실행해주어야 데이터를 크롤링하게 된다. 때문에 만약 원하는 시간에 특정 사이트에 원하는 데이터만 크롤링하고 싶으면 어떻게 해야 할까라는 생각이 들기 마련이다. 나만? 이럴 때 필요한 게 작업 스케줄러이다. mac OS와 Linux에선 cron을 이용하고 windows에선 작업 스케줄러를 이용하면 된다. 크론과 윈도우 작업 스케줄러에 대한 간단한 설명은 여기를 참고.
이렇게 간단한? Selenium을 이용한 크롤링과 MySQL DB에 크롤링 데이터를 저장하는 코드에 대해 정리했다. 사실, MySQL에 크롤링 데이터를 저장하는 것보다는 앞으로 살펴볼 다른 여러 가지 방법을 이용하는 게 낫지 않을까 싶다. 아무튼, 원래 계획은 Firebase Cloud Storage에 이미지 데이터를 저장하는 방법까지 작성하고자 했지만, 이미지 처리 라이브러리와 함께 다음 포스팅에서 알아보는 걸로~
-
오타나 잘못된 부분을 지적해주시면 감사히 생각하고 수정토록 하겠습니다 :)
- 참고 사이트
- The Hitchhiker’s Guide to python
- freeCodeCamp guide python
- The Python tutorial
- 참고 문헌
- 파이썬을 이용한 머신러닝, 딥러닝 실전 개발 입문
Subscribe via RSS